
为什么要Repair
Repair对Cassandra集群是极为重要的,因为频繁的数据删除以及机器Down掉(尽管有Hinted Handoff机制)都会可能导致数据不一致(多个副本之间)。在Cassandra日常维护中,我们要例行对集群进行Repair操作,使用nodetool的Repair命令。
Repair原理
Cassandra在Repair的操作分两个步骤:
第一: 创建Merkle tree
Merkle tree是一个二叉树,二叉树最底层是要比较的数据块的hash值,父节点是两个子节点的hash值(=hash(hash1+hash2))。二叉树的高度是15,也就是说最底层有2^15=32768个叶子节点,对应有32768个数据块,如下图所示。
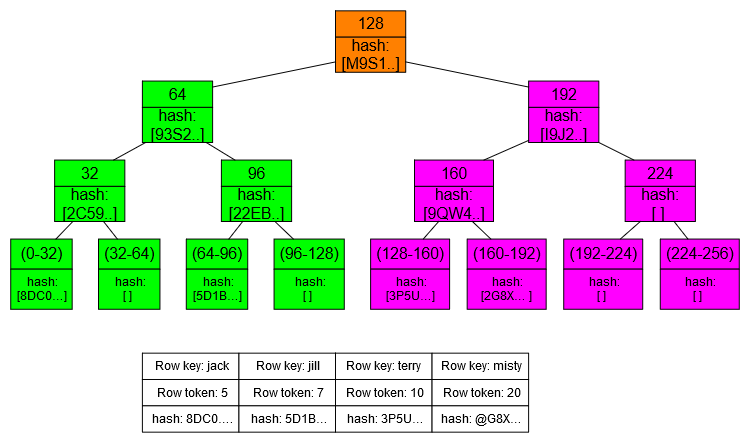
计算Merkle Tree的过程需要依赖磁盘IO。为了不影响业务,你可以限制压缩阈值(nodetool setcompactionthroughput),因为这个过程被称作validation compaction,体现在压缩任务里。
第二:比较Merkle Tree,找出差异进行数据传输。
为每个副本创建Merkle Tree以后,副本之间只要通过比较最顶端的hash是否一致,然后一层层比较下来,就可以找到不一致的那个数据库,然后进行数据传输进行修复即可。
合理分段Repair
上面的修复过程有个问题,就是Merkle Tree是存储在内存里的,所以Cassandra对高度进行了限制,只能有15层,数据只能分为32768数据块。那么这就限制了Merkle Tree的精度,假设一个节点有10万个分区key,每个数据块大约有30个,假设其中有1条数据不一致,那至少要传输30个分区key的数据。这是很浪费集群带宽和修复时间的(修复需要在gc_grace_seconds周期内完成,防止删掉的数据又出现)
Cassandra的nodetool repair提供了分段Repair的参数,-st -et分别表示token段的范围,假设我们每次repair的数据正好有32768个分区key,那么我们就可以进行精确的修复,减少不必要的传输。当我们把所有的token小段repair完毕,就相当与我们把所有数据进行了repair。
那么问题来了,怎么样对token段进行细分呢?
每个cassandra节点都有个表叫 system.size_estimates(好像是从2.1.4版本开始),在里面记录了每个表在每个token段上大约有多少分区key(partitions_count)以及每个分区key的大小(mean_partition_size)
CREATE TABLE system.size_estimates (
keyspace_name text,
table_name text,
range_start text,
range_end text,
mean_partition_size bigint,
partitions_count bigint,
PRIMARY KEY (keyspace_name, table_name, range_start, range_end)
)
你可以遍历所有的token段进行repair,遇到分区key较多的token段(大于32768),继续细分成多个子token段进行repair。
除非注明,赵岩的博客文章均为原创,转载请以链接形式标明本文地址
本文地址:https://zhaoyanblog.com/archives/1023.html
写的太棒了