
一致性hash设计出来的目的是: 根据数据的hash值把数据分布在n个节点上,当新增一个节点或者删除一个节点后根据算法重新计算,可以保证大部分数据都分布在原来节点上,只需要移动少部分数据即可。
再具体一点,当删除一个节点,只要把属于这个节点上的数据移动到其它节点上,当增加一个节点,只要从其它节点上把属于这个节点的数据自动过来。而保持不动的节点之间不需要数据移动。
下面是具体原理:
Cassandra的对数据key的hash值范围是long的最小值到long的最大值。每个节点默认负责这个单位内的256个范围。我们这里用4个范围代替。首先我们用一个圆(hash环)来表示整个hash范围。然后每个节点随机取4个点,假设我们当前有三个节点(A,B,C),如下图所示:
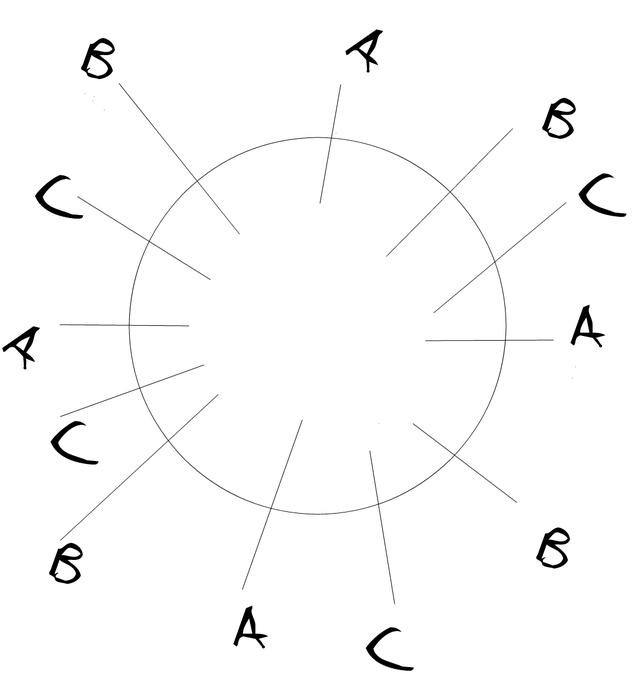
整个hash环就被分割为了12段,顺时针去看,A和B之间的hash段就属于A,B和C之间的hash段就属于B,以此类推。
一条数据的分区key的hash值落在哪个段里,就存到对应的机器上。
现在看如果要增加一个节点。我们同样在圆上增加随机的4个点。
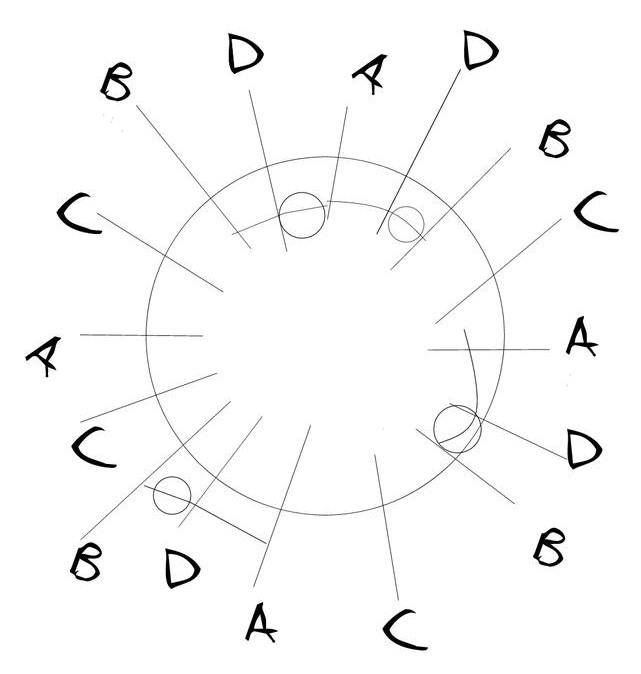
这样整个圆被分割成了16个段,同样顺时针看,我们发现大多数分段仍然属于原来的节点,只有四个小段属于了新节点D,也就是说只要移动这四个小段的数据到新节点D上,我们就完成了数据的再均衡,完成了节点扩容。
同样的如果用想退役D节点,只要把对应的分段的数据再挪回去,就完成了缩容。而大部分数据不需要移动。
这个算法就叫做一致性hash算法。
除非注明,赵岩的博客文章均为原创,转载请以链接形式标明本文地址
本文地址:https://zhaoyanblog.com/archives/1018.html