
从像apache cassandra这样的系统中,删除分布式主从复制的数据远比关系型数据库要复杂的多。当我们想到cassandra的数据是存在磁盘上的多个文件中,这个删除的过程变的超级有趣。在这样一个系统中,需要写入一个被称作墓碑(tombstone)的标记,用于记录一个删除操作,表示之前的值被删掉了。尽管你可能觉得这很不正常,或者难以理解(特别是当你意识到删除操作竟然是要占空间存储的),我们将用这篇博客,使用一些例子来解释这其中究竟发生了什么。
Cassandra:可用性和一致性的考虑
在我们深入细节之前,我们需要快速回顾一下Cassandra作为一个分布式系统是怎么工作的,特别是关于可用性和一致性。这对于我们等会解释分布式删除,以及一些潜在问题,非常有必要。
可用性:为了保证Cassandra可以复制数据,也就是说根据副本因子,存储的每一条数据都有多份拷贝。副本因子定义了每个keyspace(库的概念)在每个DC(数据中心)中的拷贝个数。通过配置,每个拷贝可以分布在不同的机架上,只要你有足够的机架,并且通过配置机架策略让系统考虑这些因素。有了这个,当任何一个节点(或者是一个机架,再说一遍,这个取决于你是否进行了配置)挂了,数据仍然可以通过其它副本进行读取。
一致性:为了确保读取数据的强一致性,我们必须遵循下面的原则:
CL.READ = 读一致性. 从至少多个节点得到读响应,我们才承认它是一个成功的操作.
CL.WRITE = 写一致性,同上.
RF = 副本因子(个数)
要满足 CL.READ + CL.WRITE > RF,只有这样,我们才能保证至少有一个写入数据的节点被读到(译者注:好有道理)
通常的例子:我们考虑下面的设置:
RF = 3
CL.READ = QUORUM = RF/2 + 1 = 2
CL.WRITE = QUORUM = RF/2 + 1 = 2
CL.READ + CL.WRITE > RF –> 4 > 3
这样的配置,就有很高的可用性,没有单点故障(SPOF),我们可以承担挂掉一个机器的风险,因为我们可以保证有一个写数据的节点可以读到,再加上最新者写入者胜出(LWW)算法(译者注:记录以写入时间戳最新的为准),就可以知道哪个节点的数据是正确的。
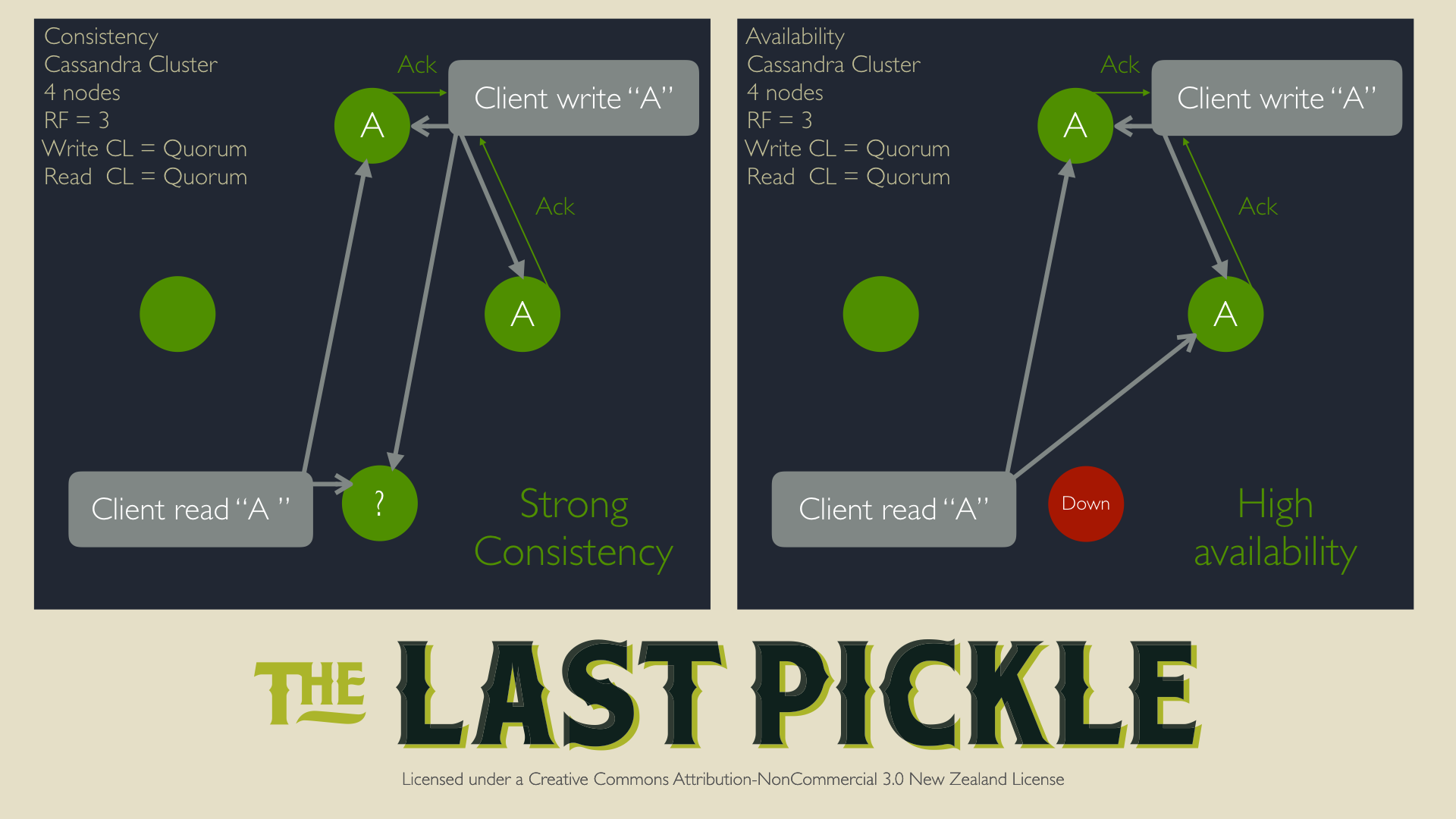
先把这种配置和做法记在脑子里,我们看一些执行删除的例子。
除非注明,赵岩的博客文章均为原创,转载请以链接形式标明本文地址
本文地址:https://zhaoyanblog.com/archives/964.html