
Cassandra的写操作包含几个过程。从开始实时写日志到最后进行压缩。
1、把数据写入commit log
2、数据写入内存表memtable
3、从memtable中刷新
4、存储到磁盘中的sstables里
5、压缩
写日志和memtable存储
当有一个写入发生,cassandra会把数据存到内存里叫memtable的数据结构里,也会写到磁盘的commitlog里,提供持久化存储。commitlog接受每个请求,并且持久化保存,甚至是断电。memtable是一种回写cache,cassandra通过key可以在memtbale里查询数据。memtable的大小是有限制的,当到达一个限制就会被刷新。
从memtable刷新数据。
当memtable的内存超过了配置的阈值,memtable里的数据包括索引,就会进入一个刷新到磁盘的队列里。你可以通过修改cassandra.yaml里的 memtable_heap_space_in_mb配置项来控制这个队列的大小。当要刷新的数据超过了队列大小,cassandra就会阻止写入直到下一个刷新成功。你可以使用nodetool flush 手动触发一个刷新,通常在重启节点之前,建议刷新一次memtable,这样可以减少重放commitlog的时间。为了刷新数据cassandra会吧memetables根据token排序,然后顺序写到磁盘上。
磁盘上数据存储到sstables中
对于在commitlog里的数据,当在memtable里的对应的数据被刷新到一个sstable中之后会被清除。
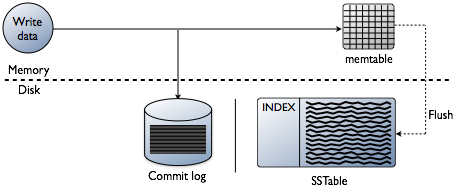
Memtables和SStables都是分表存储的,SStables是不可以改变的,当从memtbale中刷新到磁盘上后就不会再写入。因此一个分区可以通常会保存到多个sstable文件中。对于每个sstable,cassandra会创建如下结构化数据:
1、分区key索引:一个分区key的列表和对应的在data文件中的起始位置。
2、分区key汇总(在内存里):一个分区key索引的抽样
3、布隆过滤器
压缩
周期性的压缩是cassandra作为一个健康数据库所必须的,因为cassandra不会把数据插入或者更新到具体的位置。当插入或者更新发生了,并不会去覆盖原来的数据,而是重新写入一个新的时间戳版本的数据到另外一个sstable中。cassandra管理在磁盘上不断累积的sstable,就是使用压缩。
cassandra也不会去实际删除数据,因为sstable是不可以修改的。而是用墓碑的方式标记数据被删除了,墓碑存在一个可配置的周期,是表的一个参数 gc_grace_seconds。
在压缩的过程中,会有一个磁盘使用空间以及IO的临时飙升,因为老的和新的sstable会并存,这个图描述了压缩的过程:

压缩会根据分区key合并多个sstable中的数据,选择具有最新时间戳的进行存储。Cassandra可以高性能的合并数据,而不会产生随机IO,因为在sstable里的row都是根据分区key排序存储的。在删除了墓碑和要删除的数据,列和行数据后,压缩的过程会把这些sstable压缩成一个文件。老的sstable文件会在堆积到该文件上的查询请求结束后尽快的删除。这样老的sstable占用的磁盘空间又可以重复使用了。
cassandra2.1改进了压缩后的读性能,通过一种增量式的替换压缩过的sstables。而不是等到整个压缩完才去删除老的sstable。cassandra可以直接从新的sstable中读取,甚至在它完成写入之前。
当数据写到新的sstable,读请求就会访问新的sstable,在老的sstable中相应的数据不会再被访问,并且从系统的page cache中剔除掉。因此当缓存新的sstable的增量过程开始的时候,读取就不会从老的读,相应的cache也会消失。因此可以预见cassandra提供了一种高的性能甚至是在高负载下。
原文地址:https://docs.datastax.com/en/cassandra/2.1/cassandra/dml/dml_write_path_c.html
除非注明,赵岩的博客文章均为原创,转载请以链接形式标明本文地址
本文地址:http://zhaoyanblog.com/archives/926.html